




From the Community
I can't believe it's already November! Our Community has given us a lot to be thankful for!
Thanakorn Panyapiang's Two Part tutorial: Data Versioning with DVC
In his two part tutorial which can be found here and here, Thanakorn Panyapiang first explains why data versioning is so important to successful machine learning projects. Next he takes us through a tutorial of DVC showing how to install and initiate DVC. Finally he covers tracking, pushing to remote storage, modifying and switching the data. In the future look out for more posts on the other features of DVC, including pipelines, metrics, experiments and continuous integration through CML from Thanakorn!
Data Versioning with DVC

Sanaka Chathuranga: End to End Machine Learning Pipeline with MLOps tools
Shanaka Chathuranga uses multiple tools including DVC to build an end to end Machine Learning Pipeline. In the mix you'll find Cookiecutter, DVC, Mlflow, GitHub Actions, Heroku, Flask, Evidently AI, and PyTest in his post in Medium. DVC is used for data versioning and model pipeline management in this tutorial.

📣 Swag to the first person to do a similar tutorial using DVC for experiment tracking and versioning and CML for CI/CD. 🚦Go!👉🏽
COVID Genomics Apache Airflow and DVC Integration
In this blog post, Piotr Styczyński of COVID Genomics shares how they use Airflow and DVC together in their work to model SARS Cov-2 and optimizing RT-PCR tests. They needed to update the data used for the training model daily and automate their processses to make sure the whole process stays up-to-date.
Be sure to check out the very detailed tutorial with lots of delicious code and two repositories here and here.

Looking to create a light weight Feature Store?
Remember João Santiago from dvthis? Well he's back at it solving ML engineering challenges, sharing his new blog post, Unlocking Our Data with a Feature Store. In this article from the Billie.io engineering crew, Santiago shows how they implemented a light weight feature store creating a system in which features are defined in YAML files (gotta love those YAML files 😉) interfacing with Snowflake. Check out how they did it, and learn the term "instarejected" which he coined and we all should instaadopt!
Learning Opportunities
Learn about DVC en Español!
TryoLabs held an Open Meetup recently in Uraguay teaching about some of the technology they use at this consultancy. Ian Spektor, Diego Kiedanski, and Nicolás Eiris presented on the their learnings and use of DVC to get better organization of their data for the various projects they work on with their clients. In addition to streamlining the onboarding of the data for their projects, DVC has provided them reproducibility of the various data and code versions in their workflows.
Also en Español, our own David de la Iglesia Castro will be presenting at Python Barcelona on "Making MLOps Uncool Again." In this workshop David will show you how to use HuggingFace, DVC and CML to create an MLOps workflow, extending the power of Git and GitHub without the need for external platforms or complicated infrastructure.
Python Barcelona

October Office Hours Video: Continuum Industries Tool Stack with Ivan Chan
If you missed last month's Office Hours Meetup, you can now catch the video! Ivan Chan took us on a journey through the Continuum Industries tool stack and showed us how they save tons of time weekly by integrating DVC and CML into their workflows.
Are you a Data Scientist Struggling with some of the ML engineering concepts?
Atinuke Oluwabamikemi Kayode: Common Github Terms for Open Source Contributors
For the learners out there, Atinuke Oluwabamikemi Kayode's piece Common Github Terms for Open Source Contributors shares about all the most common terminology you need to know when using GitHub in your projects. Need to understand what "checkout" is? The difference between "origin" and "master?" Atinuke has you covered in this piece.
Common GitHub Terms for Open Source Contributors

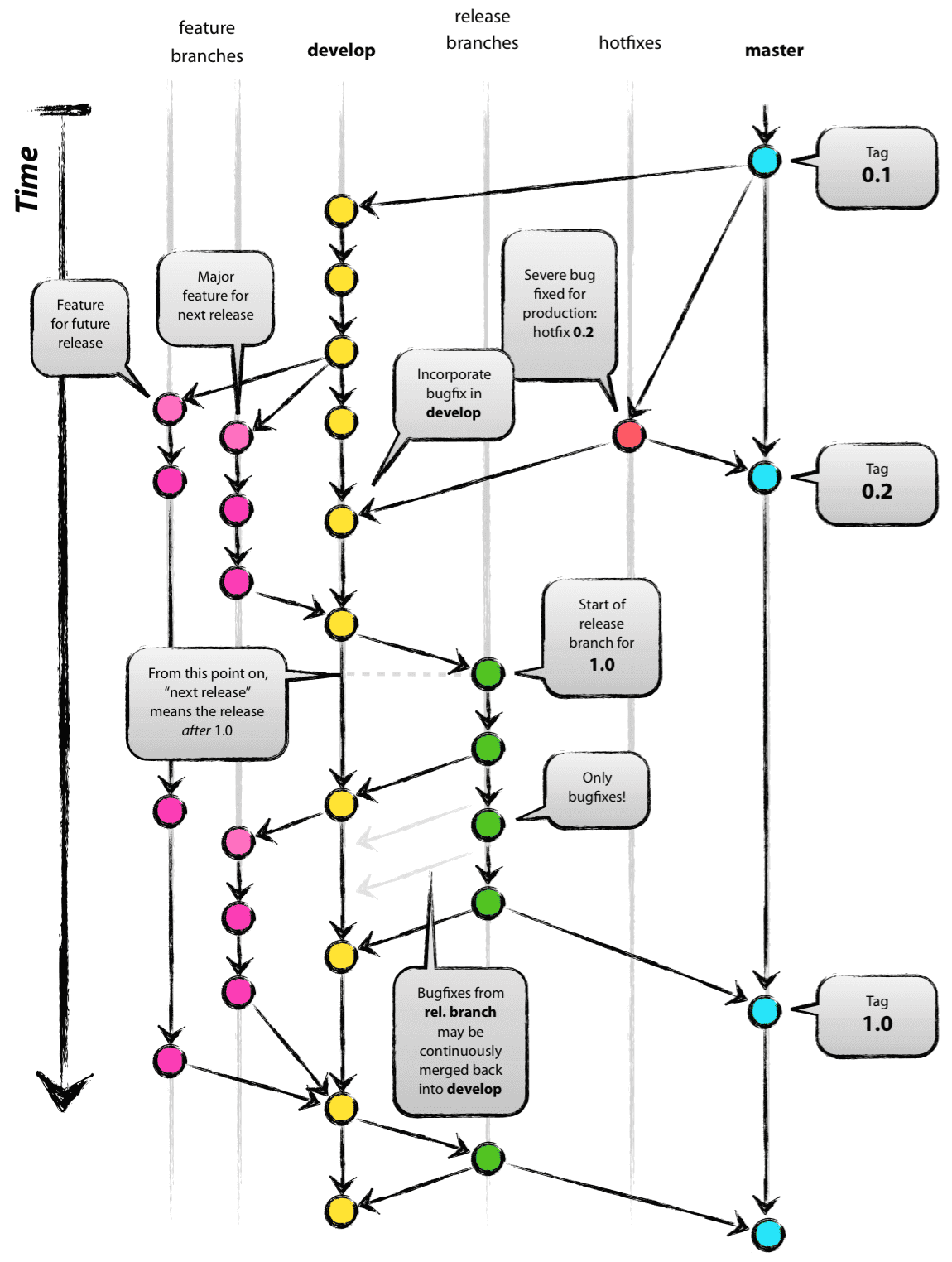
Vincent Driessen: A Successful Git Branching Architecture
For a deeper dive into how Git and versioning works, checkout A Successful Git Branching Model piece by Vincent Driessen which explains in detail the git branching model. While this explanation is as it relates to software development, it will help you understand how git versioning works. This foundation will help provide the insight into how DVC works, delivering the same capabilities for data, models and experimentation.
Nir Barazida: Notebook to Production
Nir Barazida of DAGsHub brings us a blog post on Notebook to Production which explains why you should, and how you can, move your code from notebooks to scripts when working on production ready ml projects. You'll see how DVC is used to version everything in the process so your team will always know which version of all the possible elements that go into your project produced or failed to produce the best results.
Notebook to Production

DVC Online Course Update!
We know you've wanted it, and the day is getting closer and closer! By the end of this week we will be about 90% done recording videos for the first course, and then it's on to video processing and platform set up. The first course will focus on DVC for Data Scientists and Analysts. You can expect to see the course out by the end of the year. The course will be 100% FREE and available from our website. We are so excited about how it's coming to life! 🚀
DVC News
San Francisco Off-site
The group of us from the Americas met in San Francisco last week. We had a great time getting to know each other better and working on ways and processes to make our tools even better for you! Amidst our working, we also took time out to visit Alcatraz, go on a scavenger hunt, and eat some great food! Pictured below from left front, going clockwise: Jorge Orpinel, Stephanie Roy, Ivan Shcheklein, Dmitry Petrov, Dave Berenbaum, Jervis Hui, Ken Thom, Jon Burdo, Peter Rowlands, Julie Galvan, Jeny De Figueiredo, Jordan Weber, and Maria Khalusova! 🎉

New Team Members
Maria Khalusova joins us from Montreal, Canada as a Senior Developer Advocate. Previously at Jet Brains for 14 years, Maria brings a ton of experience in developer advocacy and product management. She has already dove in working on CML and the upcoming releases. She also organizes PyData Montreal. In her free time Maria likes to spend time with her two kids, walk their mixed bull dog, and garden. 👩🏻🌾 Welcome Maria!
Open Positions
As always, we're still hiring! Use this link to find details of all the positions including:
- Senior Software Engineer (ML, Labeling, Python)
- Senior Software Engineer (ML, Labeling, Python)
- Senior Software Engineer (ML, DevTools, Python)
- Field Data Scientist / Sales Engineer
- Developer Advocate (ML)
- Director / VP of Engineering (ML, DevTools)
- Director / VP of Product (ML, Data Infra, SaaS)
- Head of Talent
- Head of DevRel
Please pass this info on to anyone you know that may fit the bill. We look forward to new team members! 🎉
Docs Updates
This month's important doc updates come from CML! The CML team has been on fire 🔥 building new things. You will want to keep your eyes tuned to CML.dev and our social media channels for big news before the end of the year!
📖 CML: Self-hosted Runners
Check out the new Self-hosted Runners doc. This will help you set up your own runners and allocate cloud computing resources. Whether you are a GitHub or GitLab user, you will be able to toggle between the respective code needed right there at your fingertips!
📖 CML: Command Reference: send-comment
The new
Command Reference: send-comment
doc provides a way for you to post a markdown comment on a commit and flags for
associating the comment with another pull/merge request or if a cml pr was
used earlier in your workflow.
📖 Branding Assets
If you are interested in writing a blog post about our tools, we now have a very
easy way for you to get your hands on our logos as well as a guide to let you
know how and where it's appropriate to use our logos and images. We love when
the Community shares about our tools!
Find our branding assets here.

Next Meetup
Be sure to join us at the December Office Hours Meetup, where we will be showing a demo on a new feature! We can't say more just yet 🤐, but be sure to RSVP!
DVC Office Hours - New Feature Release

Tweet Love ❤️
Last but never least, I leave you with this great tweet from Paige Bailey, this time about CML's docs:
🦉@DVCorg's docs are *shiny*—especially the sample code for generating reports, using either @GitHub or @GitLab.https://t.co/PKPS923HUR
— 👩💻 Paige Bailey (@DynamicWebPaige) November 13, 2021
All you have to do to auto-generate a report with metrics and plots, is include the YAML file in a .github/workflows folder in your repo. pic.twitter.com/WTSZYcLjwI
Have something great to say about our tools? We'd love to hear it! Head to this page to record or write a Testimonial! Join our Wall of Love ❤️
Do you have any use case questions or need support? Join us in Discord!
Head to the DVC Forum to discuss your ideas and best practices.