Fine-Tuning Large Language Models with a Production-Grade Pipeline
In this post, we’ll walk through an end-to-end production ML pipeline for fine-tuning large language models using several key technologies: DVC for reproducible pipelines and efficient dataset versioning, SkyPilot for launching cloud compute resources on demand, HuggingFace Transformers and other libraries for efficient transformer model training, and quantization techniques like PEFT and QLoRA for reduced precision and memory usage.





Introduction - Solving cloud resources and reproducibility for LLMs
A few of weeks ago, I wrote a post about the challenges of training large ML models, in particular:
- the need for more computing power and the complexity of managing cloud resources;
- the difficulty of keeping track of ML experiments and reproducing results.
There I proposed a solution to these problems by using SkyPilot and DVC to manage cloud resources and track experiments, respectively.
These problems are especially relevant for large language models, where both the model size and the amount of data required for training are very large. In this blog post, I will walk you through an end-to-end production-grade Machine Learning pipeline for performing Supervised Fine-Tuning (SFT) of large language models (LLMs) on conversational data. This project demonstrates the effective use of technologies like DVC, SkyPilot, HuggingFace Transformers, PEFT, TRL and others.
All the code for this project is available on GitHub:
https://github.com/alex000kim/ML-Pipeline-With-DVC-SkyPilot-HuggingFace
What’s fine-Tuning and when to use it
Let’s recap the differences between prompt engineering, prompt tuning, and model fine-tuning, three distinct approaches to working with LLMs.
Feel free to skip this section if you’re already familiar with these concepts.
Prompt engineering, prompt tuning, and model fine-tuning
Prompt engineering, prompt tuning, and model fine-tuning are three techniques for adapting large language models to downstream tasks. Prompt engineering relies on skillfully designing input prompts, often with demo examples, to steer model behavior without any parameter changes. Prompt tuning takes a more automated approach - learning continuous token embeddings as tunable prompts appended to the input. This keeps the base model frozen but allows the prompts to be optimized. Finally, model fine-tuning adapts all the model’s parameters directly through continued training on downstream data. While fine-tuning can achieve strong performance, prompt engineering and tuning offer greater parameter efficiency and model reuse. However, prompt methods may require more iteration and heuristics to work well.
Fine-tuning gives the model maximal flexibility to adapt its entire set (or a subset) of parameters directly on the new data. This end-to-end training approach is especially powerful when the target task or domain differs significantly from the original pre-training data. In such cases, extensive adaptation of the model may be required beyond what is possible through the model’s fixed input representations alone. However, fine-tuning requires re-training large models which can be computationally expensive. It also loses the ability to efficiently share one model across multiple tasks. Overall, fine-tuning tends to be preferred when maximum task performance is critical and training resources are available.
Below is a table comparing these techniques:
| Method | Description | Advantages | Disadvantages |
|---|---|---|---|
| Prompt Engineering | Skillfully designing input prompts, often with demo examples, to steer model behavior without parameter changes | • Efficient parameter reuse • No model re-training needed | • Can require much iteration and tuning • Limited flexibility to adapt model |
| Prompt Tuning | Learning continuous token embeddings as tunable prompts appended to input, keeps base model frozen | • Efficient parameter reuse • Automated prompt optimization | • Less flexible than fine-tuning • Still some manual effort needed |
| Model Fine-tuning | Adapting a subset of model parameters through continued training on new data | • Allows significant adaptation to new tasks/data • Can achieve very strong performance | • Can be difficult to set up • Computationally expensive • Loses ability to share model across tasks |
Overview of the Project
The project leverages several technologies:
- DVC for reproducible ML pipelines: This tool enables us to define the ML workflow as a Directed Acyclic Graph (DAG) of pipeline stages, with dependencies between data, models, and metrics automatically tracked. It also integrates with remote storage like S3 to efficiently version large datasets and model files.
- SkyPilot for scalable cloud infrastructure: SkyPilot simplifies the process of launching cloud compute resources on demand for development or distributed training. It supports spot instances to reduce training costs and permits the quick set up of remote interactive development environments.
- HuggingFace and other libraries for efficient training of quantized models: HuggingFace Transformers provides a simple API for training and fine-tuning large transformer models. In combination with bitsandbytes, it enables reduced-precision and quantization-aware training for greater efficiency.
The QLoRA quantization technique will allow us to apply 4-bit quantization for model weights. For Llama 7b model, this reduces GPU memory requirements from ~98 GB (with float32 precision) down to ~12 GB (with int4 precision). The screenshot below is from a handy Model Memory Calculator that helps you calculate how much vRAM is needed to train on a model that can be found on the Hugging Face Hub.

Considering the GPU memory overhead due to optimizer states, gradients, and
forward activations, we’d need around 16GB in vRAM to fine-tune a 4bit-quantized
7b model. NVIDIA A10 is a good candidate for this
(g5.2xlarge instance on AWS)
as it costs a little over $1 per hour for on-demand pricing or $0.35 per hour
for spot instance pricing.
The total training time will depend on the size of your dataset and the number of epochs you want to train for. But with this setup, I believe it's possible to train a model to achieve decent (better than the base pretrained model) performance on some narrow task for under $50 total.
For comparison, if you were fine-tuning the same model but with float16 precision, you’d need one or more NVIDIA A100 (80GB version) or H100 GPUs. Currently, they are almost impossible to get access to due to the high demand (unless you work at one of the “GPU-rich” companies). This kind of cloud hardware can be 5-10 times more expensive. For example, according to this post, it would cost you a little over $300 to fine-tune a non-quantized 7b Llama 2 model on the ShareGPT dataset for 3 epochs.
The price, of course, isn’t the only important factor. There are other low-cost Jupyter-based development environments like Google Colab or Kaggle Notebooks. While Jupyter environment is convenient when developing prototypes, the key advantage of the everything-as-code (EaC) approach proposed here is centralizing your code, datasets, hyperparameters, model weights, training infrastructure and development environment in a git repository. With LLMs being notoriously unpredictable, maintaining tight version control over training is critical.
Setup
To begin, clone the project repository. Then, install SkyPilot and DVC using pip:
$ pip install skypilot[all] dvc[all]Next, configure your cloud provider credentials. You can refer to the SkyPilot documentation for more details.
Confirm the setup with the following command:
$ sky checkAfter configuring the setup, you’ll need to download the data from the read-only remote storage in this project to your local machine, then upload it to your own bucket (where you have write access).
# Pull data from remote storage to local machine
$ dvc pull
# Configure your own bucket in .dvc/config:
# - AWS: https://iterative.ai/blog/aws-remotes-in-dvc
# - GCP: https://iterative.ai/blog/using-gcp-remotes-in-dvc
# - Azure: https://iterative.ai/blog/azure-remotes-in-dvc
# Push the data to your own bucket
$ dvc pushHuggingFace: Perform Resource Efficient Fine-Tuning
Here we’ll walk through the training approach without going into too much
detail. Please check the references at the end of this post for more information
on the techniques used. We started by loading a pretrained Llama-2 model and
tokenizer. To make training even more efficient, we used bitsandbytes and
techniques like PEFT and
QLoRA to quantize the model to 4-bit
precision.
def get_model_and_tokenizer(pretrained_model_path, use_4bit, bnb_4bit_compute_dtype, bnb_4bit_quant_type, use_nested_quant, device_map):
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=pretrained_model_path,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=pretrained_model_path,
padding_side="right",
trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizerThen we leveraged the TRL library’s Supervised Fine-tuning Trainer (SFTTrainer) to efficiently adapt the model to our target domain. The SFTTrainer provides a simple API for text generation:
def train_model(model, train_dataset, valid_dataset, lora_config, tokenizer, training_args, model_adapter_out_path):
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
peft_config=lora_config,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_args,
)
cleanup_incomplete_checkpoints(training_args.output_dir)
trainer.add_callback(CheckpointCallback())
trainer.add_callback(DVCLiveCallback(log_model="all"))
if not os.listdir(training_args.output_dir):
trainer.train()
else:
print("Resuming from checkpoint...")
trainer.train(resume_from_checkpoint=True)
trainer.model.save_pretrained(model_adapter_out_path)The quantized model can then be efficiently fine-tuned on much less capable hardware while retaining almost the same level of accuracy. By leveraging the pretrained model, tokenization, and efficient training techniques, we were able to effectively customize the model for our use case with far less resources than training from scratch. The pieces fit together nicely to enable state-of-the-art results on a budget.
DVC: Define ML Pipeline
Writing the code to efficiently fine-tune a large language model is only part of
the story. We also need to define a reproducible pipeline that can be run
multiple times with different parameters and hyperparameters. This is where DVC
comes in. Below are the stages of the pipeline defined in
dvc.yaml:
generate_identity_data: Generates a small subset of hardcoded conversational data about the model’s identity, creators, etc. saved toidentity_subset.jsonl.process_orca_data: Takes a subset of the Open Orca dataset and converts it to the prompt/completion format, saving toorca_processed_subset.jsonl.process_platypus_data: Similarly processes a subset of the Open Platypus dataset.data_split: Splits each of the 3 processed dataset files into train/validation sets.merge_data: Concatenates all the train splits and all the validation splits into finaltrain.jsonlandval.jsonl.train: Fine-tunes a Llama-2 model on the training data using the PEFT library and Supervised Fine-tuning Trainer. Saves fine-tuned model adapters.merge_model: Merges the fine-tuned adapter back into the original Llama-2 model.sanity_check: Runs a few prompts through the original and fine-tuned model for a quick sanity check.

The
params.yaml
file contains the project’s configuration values and training hyperparameters.
You can try a larger model by changing the
train.model_size
parameter to 13b (you might need to either request a larger instance or reduce
the batch size to fit in GPU memory).
SkyPilot: Run everything in Cloud
You can either develop the project and run experiments interactively in the cloud inside VS Code, or submit a run job to the cloud and pull the results to your local machine.
Developing and Running Experiments Interactively in the Cloud
To launch a cloud instance for interactive development, run:
$ sky launch -c vscode -i 60 sky-vscode.yamlThis SkyPilot command will launch a VS Code tunnel to the cloud instance.
# sky-vscode.yaml
name: sky-vscode
resources:
accelerators: A10G:1
cloud: aws
use_spot: true
workdir: .
file_mounts:
~/.ssh/id_rsa: ~/.ssh/id_rsa
~/.ssh/id_rsa.pub: ~/.ssh/id_rsa.pub
~/.gitconfig: ~/.gitconfig
setup: |
...
pip install -r requirements.txt
sudo snap install --classic code
...
run: |
code tunnel --accept-server-license-termsOnce the tunnel is created, you can open the VS Code instance in your browser by clicking the link in the terminal output.
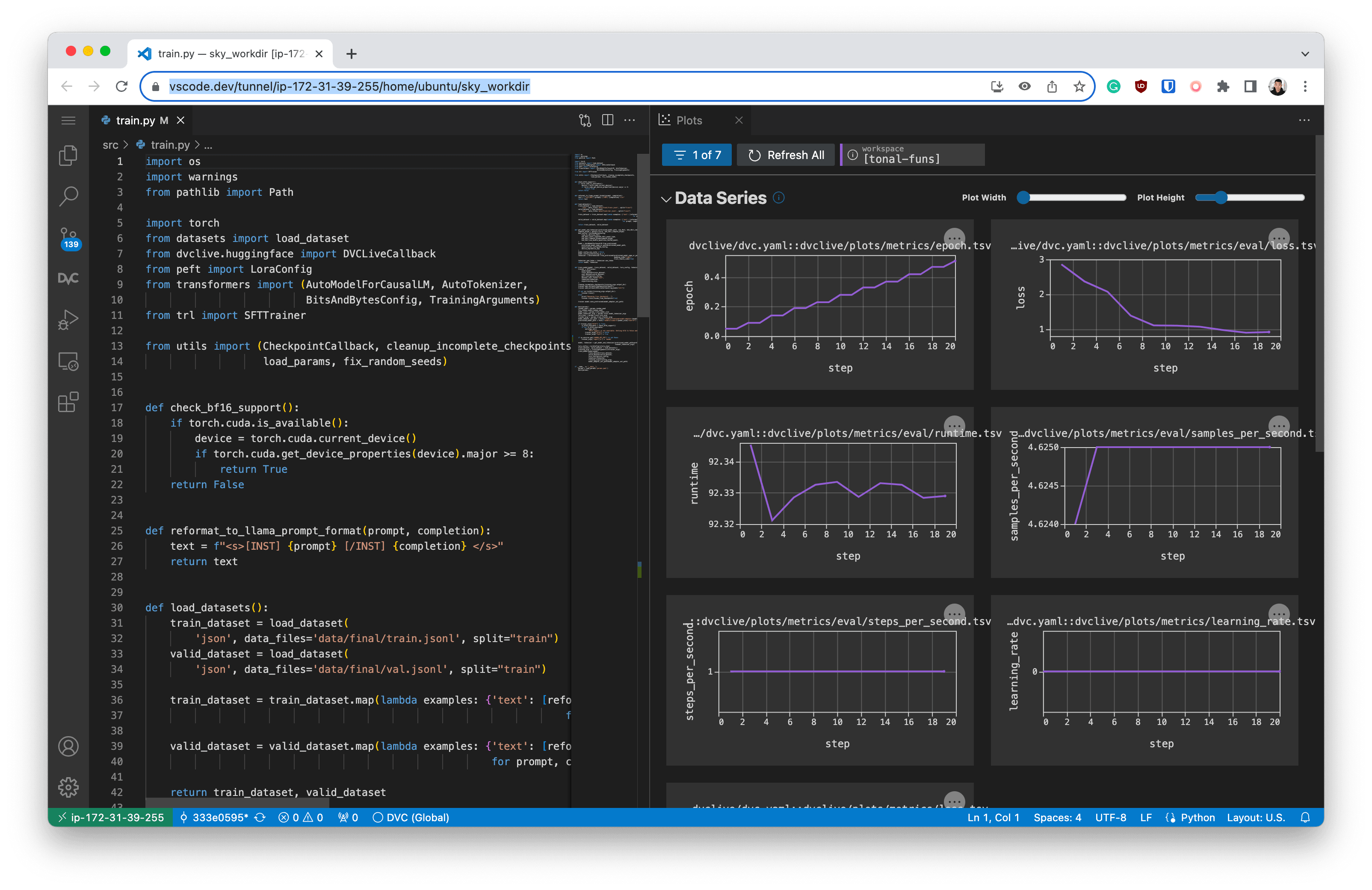
Submitting Experiment Jobs to the Cloud
When you are ready to launch a long-running training job, run:
$ sky launch -c train --use-spot -i 30 --down sky-training.yamlThis SkyPilot command uses spot instances to save costs and automatically
terminates the instance after 30 minutes of idleness. Once the experiment is
complete, its artifacts such as model weights and metrics are stored in your
bucket (thanks to the dvc exp push origin command in sky-training.yaml).
# sky-training.yaml
name: sky-training
resources:
accelerators: A10G:1
cpus: 8
cloud: aws
disk_size: 1024
workdir: .
file_mounts:
~/.ssh/id_rsa: ~/.ssh/id_rsa
~/.ssh/id_rsa.pub: ~/.ssh/id_rsa.pub
~/.gitconfig: ~/.gitconfig
setup: |
pip install --upgrade pip
pip install -r requirements.txt
run: |
dvc exp run --pull
dvc exp push originWhile the model is training you can monitor the logs by running the following command.
$ sky logs train
...
(sky-training, pid=25305) 52%|█████▏ | 28/54 [00:20<01:01, 2.38s/it]
(sky-training, pid=25305) 54%|█████▎ | 29/54 [00:22<00:56, 2.28s/it]
(sky-training, pid=25305) 56%|█████▌ | 30/54 [00:25<00:57, 2.39s/it]
(sky-training, pid=25305) 57%|█████▋ | 31/54 [00:28<01:01, 2.67s/it]
...Then, you can pull the results of the experiment to your local machine by running:
$ dvc exp pull originCustomizing the Cloud Instance and Parameters
-
You can change the cloud provider and instance type in the
resourcessection ofsky-training.yamlorsky-vscode.yaml. -
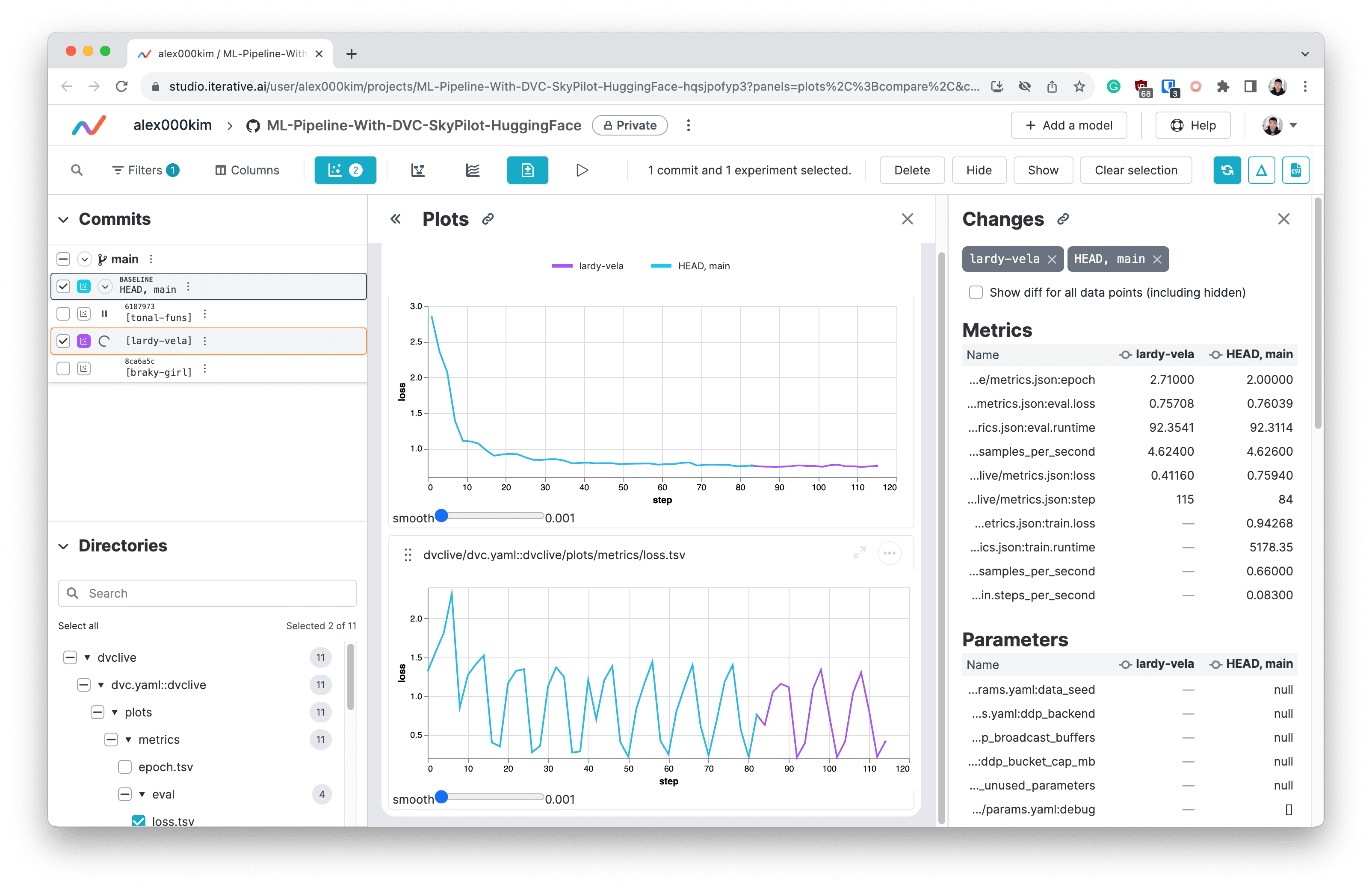
To enable DVC Studio integration, for real-time monitoring of metrics and plots, add the
--env DVC_STUDIO_TOKENoption to thesky launchcommands above.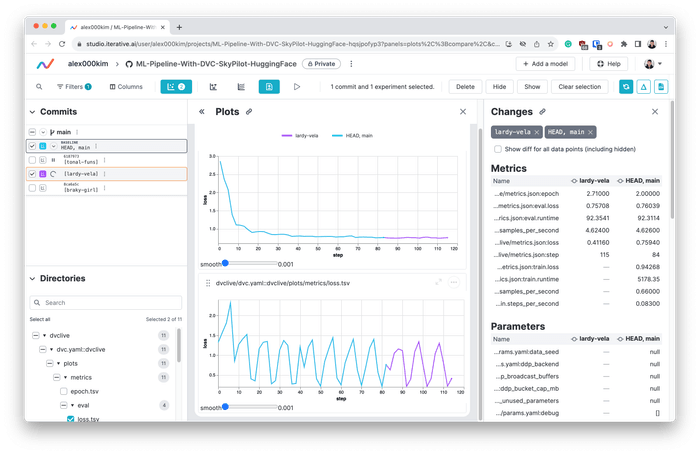
-
To enable Weights & Biases integration, add the
--env WANDB_API_KEYoption to thesky launchcommands above.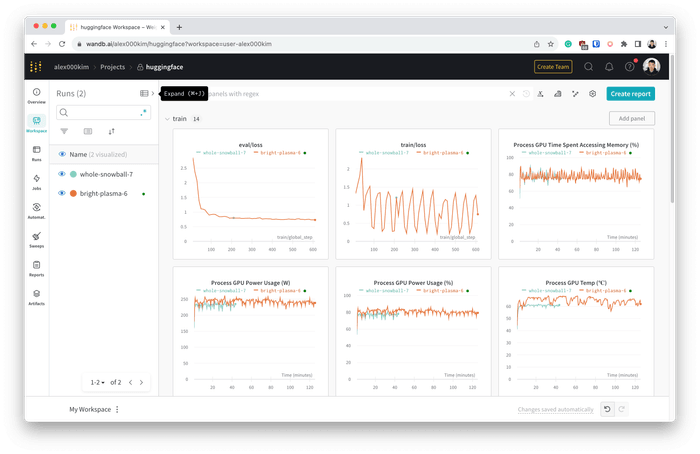
Summary
In this post, we walked through an end-to-end production ML pipeline for fine-tuning large language models using several key technologies:
- DVC for reproducible pipelines and efficient dataset versioning
- SkyPilot for launching cloud compute resources on demand
- HuggingFace Transformers and other libraries for efficient transformer model training
- Quantization techniques like PEFT and QLoRA for reduced precision and memory usage
We used the everything-as-code (EaC) approach of centralizing code, datasets, hyperparameters, model weights, training infrastructure and development environment in a git repository. Even the most subtle changes to the training setup will be recorded in the git history.
We started with a pretrained Llama-2 model and used bitsandbytes to quantize
it for 4-bit precision. Then, we leveraged the TRL library’s Supervised
Fine-tuning Trainer with PEFT for efficient domain-specific fine-tuning.
The resulting pipeline enables state-of-the-art LLM capabilities to be customized for a target use case with modest compute requirements. DVC and SkyPilot enabled this to be built as a reproducible ML workflow using cloud resources efficiently.
This demonstrates how proper MLOps tooling and techniques can make large language model fine-tuning achievable even with limited resources. The modular design also makes it easy to swap components like the model architecture, training method, or cloud provider.
References
- PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA
- Fine-Tuning Llama-2: A Comprehensive Case Study for Tailoring Models to Unique Applications
- Fine-Tune Your Own Llama 2 Model in a Colab Notebook
- Finetuning Llama 2 in your own cloud environment, privately