Organize Your Storage with DVC Cloud Versioning
Major cloud providers (AWS, Azure, Google) all have versioning capabilities, but they only version individual files. DVC can help you track the cloud version IDs across many files for all the datasets and models in your project.





If you use cloud storage regularly, you have probably seen it become a mess like this S3 bucket:
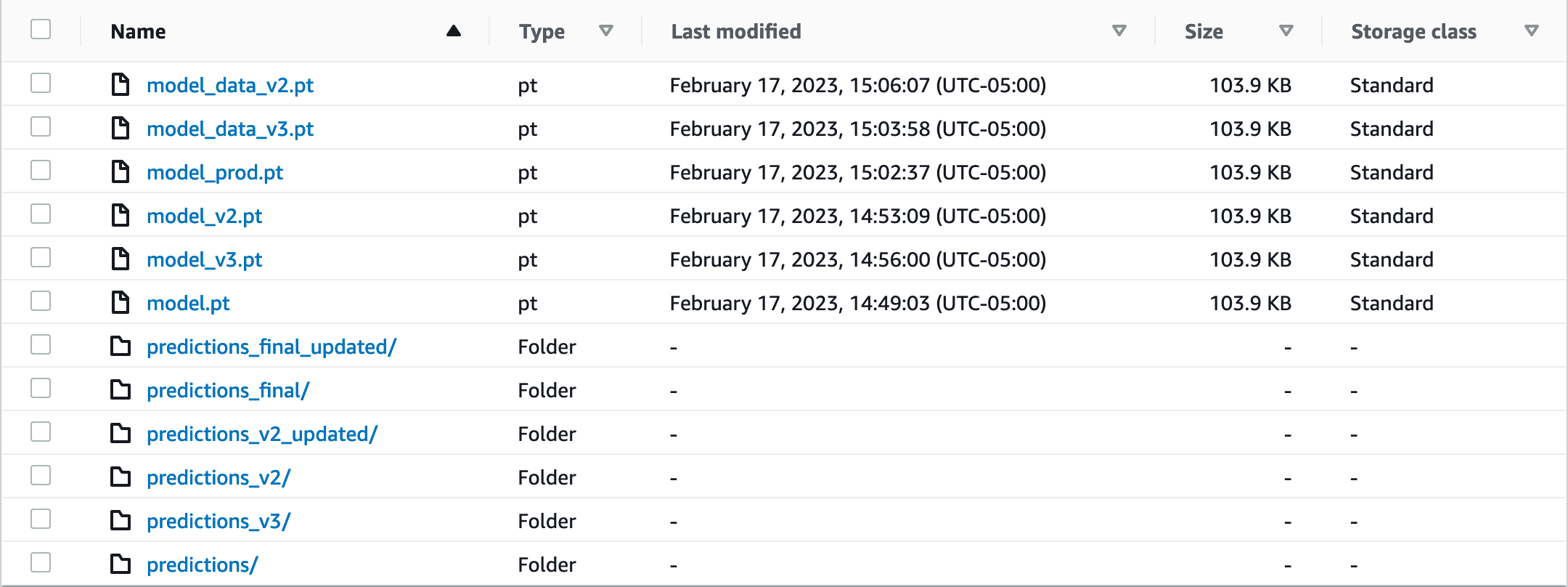
Luckily, major cloud storage providers can version files automatically. Still, even with versioning enabled, you might find you end up with a mess. More importantly, you forget which version is which.
That's because versioning happens at the file level. There's no way to version a composite dataset or entire machine learning project. This is where DVC can supplement cloud versioning and finally let you clean up your cloud storage. DVC records the versions of all the files in your dataset, so you have a complete snapshot of each point in time. You can store this record in Git alongside the rest of your project and use it to recover the data from that time, giving you the freedom to keep adding new data in place without fear of losing track of the old data. DVC ensures reproducibility while keeping everything organized between your Git repo and cloud storage, so you can focus on iterating on your machine learning project.
If you already use DVC, you might be familiar with data versioning and want to know what DVC cloud versioning means for you. Read the next section to get more familiar with cloud versioning generally or skip directly to the section for existing DVC users.
How cloud versioning works
With versioning enabled, whenever you save a file to the cloud, it will get a unique version ID. When you overwrite (or even delete) a file, the previous version remains accessible by referencing its version ID.
Here's the same data from above organized with cloud versioning:
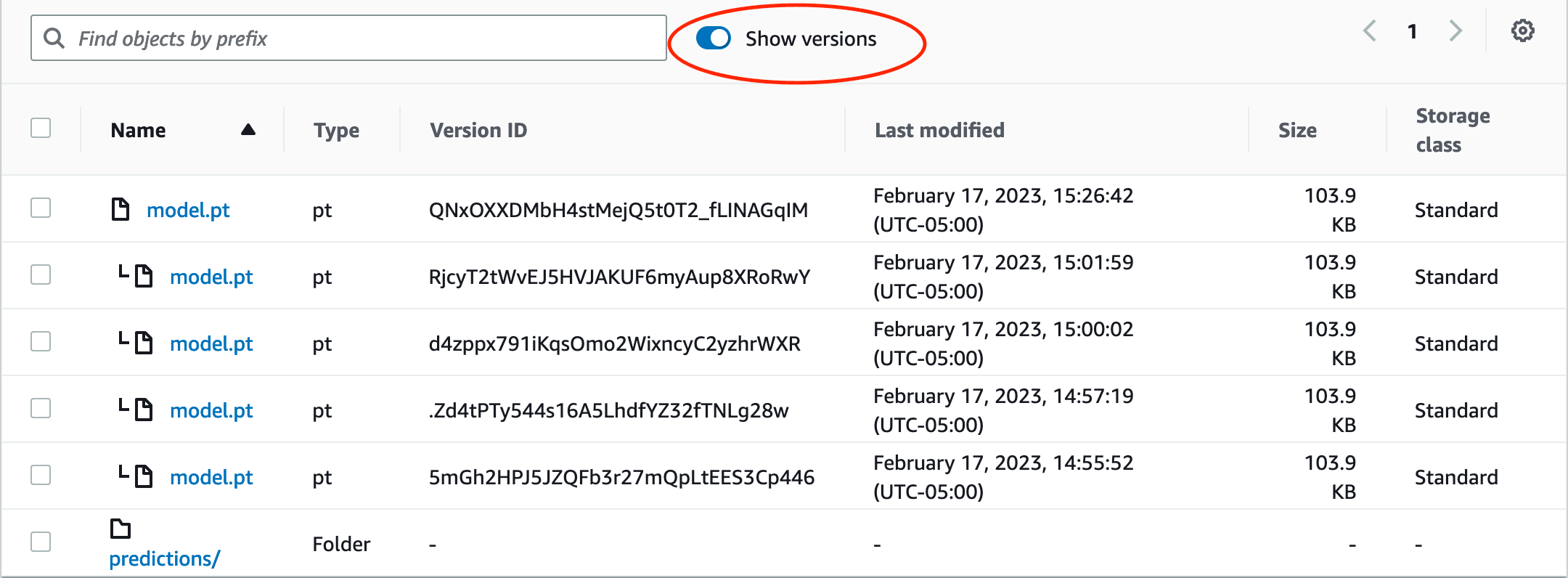
And here it is showing only the current versions:

Now the model versions are all collapsed under one file name and ordered by
time, but what about the predictions folder? Let's assume this project trains
a neural machine translation model, and each file in predictions is a
predicted translation of a sentence. Each model iteration generates a new set of
predictions. How can we reassemble the predictions from an earlier model
version?

How DVC works with cloud versioning
Cloud versioning falls short for tracking and syncing folders and projects, but this is where DVC can help. DVC records the version IDs of all files in your dataset or project. You keep this record in a Git repository so you can maintain snapshots of your cloud-versioned data (the data itself gets stored on the cloud, not in Git).
Before you start with DVC, ensure that your cloud storage is configured correctly. Cloud versioning must be enabled at the bucket or storage account level. See Quickstart for instructions below if versioning is not already enabled. You also need write access to the cloud storage (more info on how to configure your storage here).
To start using cloud versioning in DVC, install
DVC and set up a version_aware remote inside a Git repo. A remote is the cloud
storage location where you want to sync the data, and version_aware tells DVC
to use cloud versioning.
$ dvc init
$ dvc remote add --default myremote s3://cloud-versioned-bucket/path
$ dvc remote modify myremote version_aware trueUse dvc add to start tracking your model and predictions and dvc push to
sync it to the cloud.
$ dvc add model.pt predictions
$ dvc push
11 files pushedIf you want to start tracking changes to an existing cloud dataset instead of starting from a local copy, see dvc import-url —version-aware.
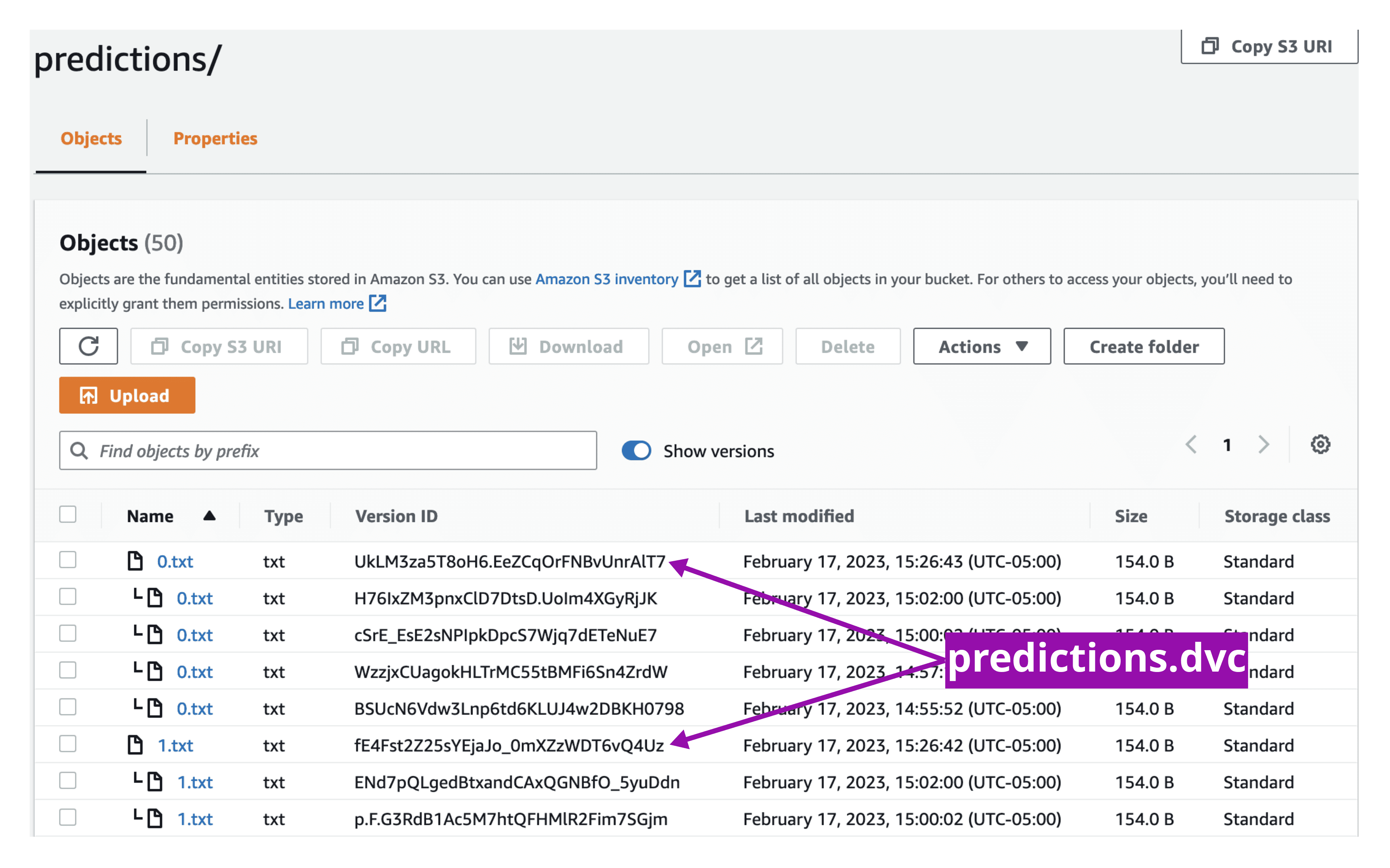
DVC adds model.pt.dvc and predictions.dvc files with the version ID (and
other metadata) of each file.
outs:
- path: predictions
files:
- relpath: 0.txt
md5: f163358b0b2b89281d6990e82495d6ca
size: 154
cloud:
myremote:
etag: f163358b0b2b89281d6990e82495d6ca
version_id: UkLM3za5T8oH6.EeZCqOrFNBvUnrAlT7
- relpath: 1.txt
md5: ec736fcb3b92886399f3577eac2163bb
size: 154
cloud:
myremote:
etag: ec736fcb3b92886399f3577eac2163bb
version_id: fE4Fst2Z25sYEjaJo_0mXZzWDT6vQ4UzNext, track model.pt.dvc and predictions.dvc in Git.
$ git add model.pt.dvc predictions.dvc .gitignore
$ git commit -m "added and pushed model and predictions"DVC will also make Git ignore model.pt and the predictions folder so that
Git only tracks the metadata. For more info on the mechanics of how DVC works,
see
Versioning Data and Models.
Now there is a versioned record of the model and predictions in Git commits, and we can revert to any of them without having to manually track version IDs. If someone else clones the Git repo, they can pull the exact versions pushed with that commit, even if those have been overwritten in cloud storage.
$ git clone [email protected]:iterative/myrepo
$ cd myrepo
$ dvc pull
A predictions/
A model.pt
2 files added and 11 files fetchedFor existing DVC users
If you have versioning enabled on your cloud storage (or can enable it), you may
wish to start using version_aware remotes to simplify the structure of your
remote (or so you don't have to explain that structure to your colleagues). A
version_aware remote is similar to the remotes you already use, except easier
to read.
A traditional cache-like DVC remote looks like:

A cloud-versioned remote looks like:
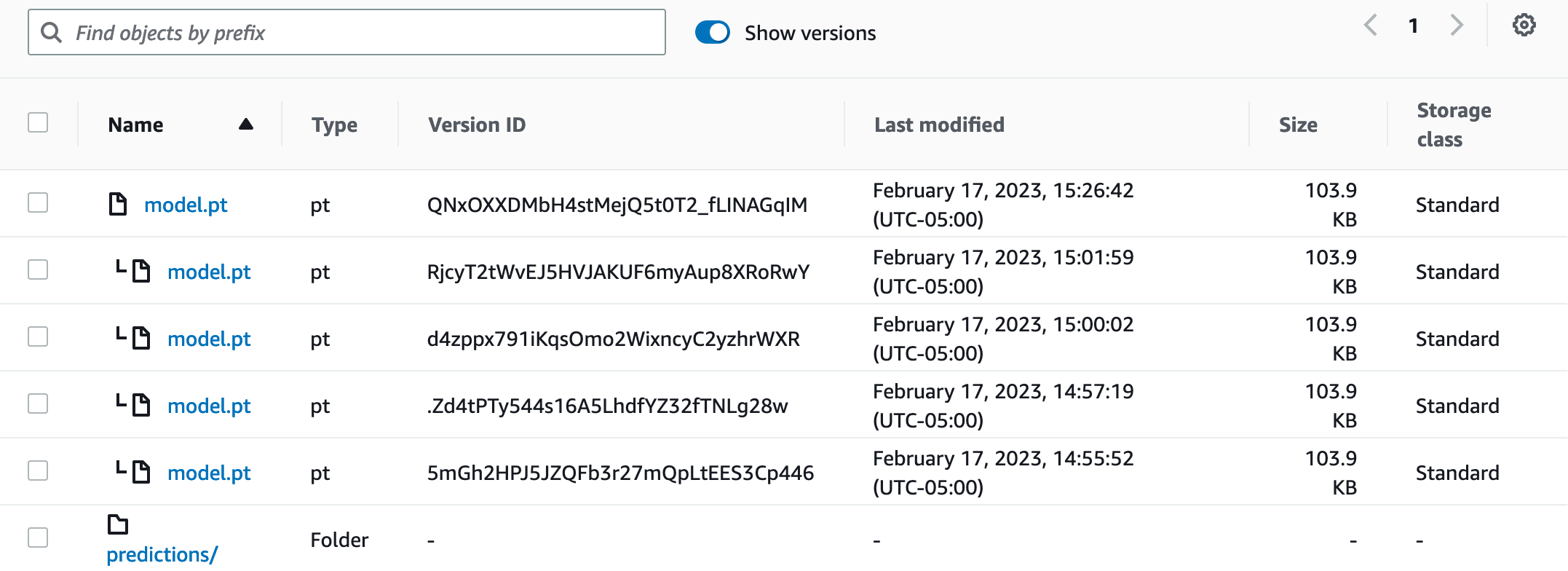
The other difference is that version IDs get added to the
DVC metafiles during
dvc push.
outs:
- path: predictions
files:
- relpath: 0.txt
md5: f163358b0b2b89281d6990e82495d6ca
size: 154
cloud:
myremote:
etag: f163358b0b2b89281d6990e82495d6ca
version_id: UkLM3za5T8oH6.EeZCqOrFNBvUnrAlT7
- relpath: 1.txt
md5: ec736fcb3b92886399f3577eac2163bb
size: 154
cloud:
myremote:
etag: ec736fcb3b92886399f3577eac2163bb
version_id: fE4Fst2Z25sYEjaJo_0mXZzWDT6vQ4UzThis means you need to be more careful about the order in which you dvc push
and git commit. You should first dvc push and then git commit since
pushing will modify the DVC metafiles. This might seem odd, but it means you
have a record in Git of what was pushed, so there is no more guessing whether
you remembered to push.
Quickstart
You can start with DVC cloud versioning in 3 steps:
1. Check whether cloud versioning is enabled for your bucket/storage account, and enable it if it's not.
2. Setup DVC to use that bucket/container as cloud-versioned remote storage.
$ dvc init
$ dvc remote add --default myremote s3://cloud-versioned-bucket/path
$ dvc remote modify myremote version_aware true3. Add and then push data.
$ dvc add model.pt predictions
$ dvc pushStop messing around with backing up your cloud data! With cloud versioning in DVC, you can iterate on your data as much as you want without losing track of your changes or worrying about your storage growing into an unmanageable mess.
Special thanks to Peter Rowlands for leading the development of this new capability!